From Floppies to Repository: A Transition of Bits
A Case Study in Preserving the Michael Joyce Digital Papers at the Harry Ransom Center
Thomas Kiehne, Vivian Spoliansky, Catherine Stollar
The University of Texas at Austin
In January of 2005, three students at the University of Texas at Austin School of Information undertook a project to preserve the electronic files of hypertext author Michael Joyce for the Harry Ransom Center, an art and humanities focused archives located on the UT campus. Thomas Kiehne, Vivian Spoliansky and Catherine Stollar, the students involved in the project, spent five months preparing, arranging, describing and ingesting—into an Open Archival Information System (OAIS) called DSpace—Joyce’s digital files for preservation. The following is a report on the methods, problems and suggestions we developed while participating in the Joyce Project.
Background
The Harry Ransom Center
The Harry Ransom Center, custodian of the Michael Joyce Digital Papers, is an archives focused on advancing the study of the arts and humanities. Fulfilling the core of its mission the Harry Ransom Center:
-
Acquires original cultural material for the purposes of scholarship, education, and delight
-
Preserves and makes accessible these creations of our cultural heritage through the highest standards of cataloging, conservation, and collection management
-
Supports research through public services, symposia, publications, and fellowships
-
Provides education and enrichment for scholars, students, and the public at large through exhibitions, public performances, and lectures.
In acquiring the Michael Joyce archive, the Harry Ransom center has the opportunity to preserve rare and unique electronic files that document the creation and evolution of hypertext fiction. The earliest of Joyce’s files were created in the mid-1980s, thereby necessitating the speedy creation of a digital preservation strategy to prevent the loss of some files to medial failure or software inoperability.
Michael Joyce
“Michael Joyce is the author of afternoon, a story, perhaps the most celebrated hypertext fiction written to date, and of Twilight, A Symphony. His first novel, The War Outside Ireland (1982), was a Small Press Book Club selection, won the Great Lakes New Writers Award in fiction, and was featured in the USIA international traveling exhibit, "America's Best." He holds an MFA from the Iowa Writers Workshop, where he was a Teaching Writing Fellow; and he has been a Visiting Fellow at the Yale University Artificial Intelligence Project (1984-85). With Jay Bolter and John B. Smith, he developed Storyspace.” (from http://www.eastgate.com/people/Joyce.html, accessed 05/08/05)
Michael Joyce has also played an important role in the evolution of hypertext as a teacher. He began his teaching career in 1975 at Jackson Community College in Jackson, Michigan where he served as Associate Professor and Coordinator of the Center for Narrative and Technology until 1995. Currently, he is a faculty member at Vassar College where he continues to teach students the potential of the relationship between narrative and technology. Hypertext offers its users new tools and methods for textual collaboration, education, learning and entertainment.
Just as hypertext facilitates new relationships between narrative and technology, digital preservation requires relationships to form between traditional archival practice and technology. Thus making hypertext an ideal narrative form, and Michael Joyce an ideal author, with which to begin digital preservation at the Harry Ransom Center.
Data Recovery and Preparation (Digital Archeology)
Many of the procedures that were used to extract and identify the electronic records were dictated by the characteristics of the storage media. The assumption at this stage is that the original storage media is not stable or reliable and the information that they hold must be moved quickly and efficiently. Otherwise, little was known about what to expect in terms of specific technological issues or requirements.
The provided floppy discs were mostly from the Macintosh “classic” era, some of which date as far back as the mid to late 1980s. Recent and current Macintosh hardware no longer have floppy drives installed. During our exploratory tests using a Mac OS X computer with an external USB floppy drive we had some difficulty in accessing the discs. Many of the floppies came to us labeled “unreadable” we suspect because of this very problem. Fortunately, older Macintosh hardware with integrated floppy drives were readily available and proved to be perfectly able to access the contents of the discs. From this experience it was decided to try to migrate the content of the discs using older hardware and Macintosh operating systems that are somewhat contemporary with the computing environments originally used to create the information. This decision would also prove to be helpful in the appraisal phase of the project when trying to access documents extracted from the discs – something that would not have been possible in many cases using recent Macintosh operating systems without conversion or migration utilities.
In addition to the hardware and operating system environment, we desired to use only open source, shareware, or freeware tools that are readily available in order to assist with the extraction process. This decision is characterized by several factors. First, we wished to eliminate the time required to create new programs to perform specific tasks or groups of tasks. Second, we wished to assess the state of existing tools for use in file management and assessment. Finally, we wanted to mitigate the effect of not knowing in advance what tasks we might perform and what tools might be necessary to perform them.
The Digital Archeology Process
In general, the process of extracting information was performed in the following steps:
-
Receive and identify physical media
-
Create a cataloging system for the physical media
-
Copy files from physical media and record metadata
-
Perform initial file processing
-
Create an item-level listing of all recovered files
-
Create working copies of all files and protect the original copies
The process is not necessarily linear, as is evident in the discussion of each step below.
Receive and identify physical media: We initially received packages of floppy discs that were arranged by a student intern working for Michael Joyce. We had to assume that these groupings reflected, in some way, the order in which the discs were originally stored or arranged. Each bundle was labeled in various ways, some having to do with some sort of semantic ordering ('STARWHITE”, etc.), and others with functional indicators (“UNREADABLE”). We could infer no explicit ordering other than that of the labeling, so the order in which we encountered the disc bundles became our original order.
As the discs were unpacked and placed into suitable containers, a sequential number was written in pencil on the outside of the disc housing that reflected the bundle and sequence of the disc within that bundle, e.g.: 13.1 for the first disc in the thirteenth bundle. This number is later referred to as the disc's catalog number, or more simply, disc number.
Create a cataloging system for the physical media: In order to begin gathering metadata, a Microsoft Excel spreadsheet was created that was be used to inventory and describe various attributes about the discs. The following fields were chosen: disc number, bundle name, written (physical) disc label, virtual disc label, disc creation date, disc checked date, contents copied date, and notes.
The purpose for the various date fields was to ensure that several individuals could work on processing the discs independently and not duplicate effort. The notes field was used to communicate problems that were encountered to other group members and to record technical notes about any corrective actions taken.
Copy files from physical media and record metadata: Once the media were organized and a method for collecting metadata was established, the contents of the discs were copied to a directory on the workstation’s hard drive. The procedure for each disc was as follows:
-
Select the next disc from the container
-
Enter the disc number and written label into the spreadsheet
-
Insert the disc into the drive
-
If the disc is accessible (i.e.: formatted and without errors), record the virtual label (that which appears with the disc icon) into the spreadsheet.
-
Create a new sub-directory in the working directory and label it with the disc number
-
Drag-and-drop the disc icon into the new sub-directory. On a Macintosh, this creates a directory bearing the name and creation date of the disc. Were we using a Windows workstation, the directory would have to be manually created and the contents copied separately.
-
Update the creation date, date checked, and date copied in the spreadsheet.
-
If there are any problems, such as a file copy error, note them in the notes field of the spreadsheet.
The result of this process is a well organized grouping of electronic files that mirrors the organization of the physical discs, and which contains some metadata in the directory structure, specifically, the virtual label, the creation date of the disc, and the date on which the disc was processed. Should the spreadsheet become corrupted, lost, or otherwise unusable, much of the information can be regenerated from the directory structure itself.
At the end of each work session, a copy was made of the working directory and spreadsheet to removable media to protect against loss due to hard drive or system failure on the workstation.
Perform initial file processing: There are two types of initial file processing that occur during this step: virus checking and file recovery. Virus checking should be performed interactively, that is, any actions attempted by the software should require intervention by a user to make any changes to a file. Ideally, virus checking should happen automatically upon copying files from disc to hard drive, but barring this, a virus check should be performed on all copied files prior to any interactions with them to avoid infection of other files. It should also be noted that the virus checking software should be able to identify viruses that are contemporary with the information being processed – in our case, the mid-1980s to mid-1990s. Additionally, prudence suggests that the processing workstation be isolated from interactions with networks as much as possible during this phase to protect against newer, network based hazards.
The second type of file processing occurs when copying is prevented due to disc or file errors. These errors can occur for a number of reasons, including damaged media, exposure to magnetic or other hazards, dirty data surface areas, and so on. In the case of dirty surface areas, several attempts may be needed to overcome a copy error. It is suggested to have a drive cleaning kit available and use it periodically to prevent build up of debris on the drive head. For other errors, it is necessary to have available software utilities that can attempt to recover from file copying errors. Windows provides such capabilities within the operating system (e.g.: Scandisk), but Macintosh does not. For our purposes we were able to discover an older version of a commercial program, Norton Utilities, which allowed us to recover many files that could not be copied initially.
Detailed information about actions taken to recover from a file copy error or virus were recorded in the disc catalog. This included identifying any files that could not be recovered, and, in several cases, when directory structures had to be manually recreated due to unavoidable directory copying errors. This metadata is used later during the repository ingest process to augment the provenance statement for the affected files.
Create an item-level listing of all recovered files: At this point, there will be a complete copy of the contents of the discs and an accompanying document of metadata at the disc level. Since digital preservation operates at the item level, it is essential to generate metadata for each item. Fortunately, our hierarchical arrangement allows us to use file system tools to generate some of the metadata automatically. There are a number of freeware, shareware, and commercial applications for Macintosh that will catalog a file volume and produce reports. We used a shareware utility called CatFinder (http://www.mindspring.com/~shdtree/newsite/id9.html) to index the copied files and export a report to a delimited format that was imported into Excel. This report formed the basis of our item-level metadata, including fields for filename, file size, kind (document or folder), Macintosh file type (analogous to the Windows file extension), Macintosh creator code, creation date, and modification date. To this basic report we added a comments field for use during appraisal.
MD5 file hashes were also generated for each file. Having an MD5 hash for each file allows us to do two important things: to identify and/or eliminate redundant files, and to support provenance auditing during the repository ingest process. A freeware PERL application called Integrity (http://therockquarry.com/integrity.htm) provided batch MD5 hash calculations and report exporting capabilities. Unfortunately, integrating the two reports was not trivial due to differences between the two applications in file name recursion and omission of hidden files.
Create working copies of all files and protect the original copies: Before proceeding with appraisal, it is necessary to create a copy of the copies in order to avoid having to recover files from the original media in the event of inadvertent file corruption or damage during appraisal. The wisdom of this decision was demonstrated once during the project when we attempted to access a disc that had already been copied and were presented with disc format prompt! Remember: we are assuming that the original media are not stable or reliable, so we do not wish to access them any more than necessary. The original bit copies should be made read-only or locked by the file system to ensure that the original copies will remain unmodified. This is also a good time to create a copy of all the files on removable media along with a copy of the file and disc level indexes.
Observations on the Digital Archeology Process
The process just described is effective and reliable so long as all participants in the process are diligent and consistent in their actions. The use of spreadsheets for file indexing and metadata collection is highly effective in that it allows team members to track issues that arise, presents a familiar and intuitive user interface for data collection, and can be easily exported and manipulated. Unfortunately, once the appraisal process begins, the file hierarchy changes as files are removed, moved, or altered in accordance with collection development. The end result is that the original file index no longer represents the working directory structure and must be regenerated at the completion of the appraisal process. This is not a problem in itself, but creates a challenge in trying to carry forward the comments and other notes from the original file index. In our case it was relatively simple to manually copy these notes, but in a case where a larger number of files or discs are involved, or if an institution must frequently perform digital archeology, a more robust solution must be implemented to track the process. A database or Web-based application could easily be developed to track each file from its original physical location through appraisal and ingest. Data entry for a database application might demand more effort initially, but will reduce error and effort later in the process.
A number of choices may be made about the depth and veracity of metadata generation. For example, we captured only the prevailing physical labeling on each disc. It is possible however to go further with physical description, including notes about scratched-out or previous disc labels, disc types and capacity (e.g.: double-sided, 800 Kb), and other such externalities. An especially eager archivist may decide to scan or photograph the disc itself and include an image in the repository for posterity. Furthermore, the operating system may include additional attributes that cannot be captured by a simple file listing. For example, Macintosh files and directories may have customized icons or priority (color) labeling. The depth of description is ultimately a judgment call on the part of the archivist, who should consider the time and resources available for the project against the added benefit of richer description in the context of the collection's purpose.
A second metadata issue involves file and disc creation dates. As indicated earlier, Macintosh's Hierarchical File System (HFS) supports disc creation dates while Windows' File Allocation Table (FAT) does not. Additionally, when a Macintosh file is copied, the creation date of the original is maintained while a copy performed in Windows resets the file creation date to the date of copy. This subtle difference forced us to manually adjust metadata for files copied from FAT formatted discs and files copied using a Windows workstation. We made note of the change in the comments field to inform provenance, but such a fundamental difference is sure to cause issues for similar projects performed in completely Windows-based environments. Solutions to the creation date problem must be found, possibly in the form of new copy utilities for use in Windows environments.
Other issues with dates were encountered that illustrated some very basic assumptions about digital information. Two types of date errors were encountered: dates that were obviously incorrect (e.g.: 01/26/1904, 04/27/1957). These anomalies most likely occur as a result of two problems. The first problem is corruption of the file's resource fork. Although the error can be fixed, the date cannot be recovered – the repair process merely resets the date to the current date. The second problem is an incorrectly set internal clock on the creator's computer. In extreme cases, such incorrect dates are easy to discover and discount, but they bring to bear a fundamental assumption in digital archeology: we assume that the date provided by the original user is correct. This is really no different than the analogous case in physical archives, where dates are written on paper as best the creator can recall and are subject to error. The lesson learned here is that although digitally assigned dates may be reliable in most cases, they are not immune to error and must be taken as a best estimate rather than indisputable fact.
Perhaps the most pertinent observation is that although there are tools available to automatically generate file metadata, they do not work especially well together. We used separate applications to generate file listings, MD5 hashes, check for viruses, and recover from file system errors. If an organization is going to frequently participate in digital archeology, it is advisable that tools be sought or developed that can perform many of these tasks simultaneously. Ideally, these tools would work with the database application suggested above to reduce human intervention, and therefore, time and error. Regardless of what form these tools take, a kit of such tools must be procured for each operating system environment in which digital archeology is to be performed, even if the operating system environment exists as an emulator. Given that numerous operating systems are currently bordering on obscurity, it is imperative that archives gather these tools sooner rather than later. The loss of access to such tools is equivalent to allowing data created in those environments to die, every bit as much as failing to take any action at all to recover the data.
A final observation concerns the affordances of the storage technology from which we recovered information. An interesting longitudinal study could compare the changes in information management practices as storage media capacities and types changed. Specifically, the 800 to 1400 kB storage capacity of the floppies used in the 1980s and 1990s enforced certain organizational practices that disappeared rapidly with the advent of large capacity hard drives. Subdirectories are much rarer on floppies than hard drives and other large capacity media; therefore, we saw little need to retain structural information beyond the disc ID and label. Digital archaeologists working with hard drives and large capacity storage media should collect path data as it will assist in file tracking and identification as well as in establishing the original order and contextual information necessary for appraisal.
Arrangement of the Joyce Files
While copying bits from floppies to a hard drive, we were able to quickly survey the types of materials and some file content to help us develop an arrangement for the files based on the functions in which the files were created. We tried to model the arrangement of the Joyce files after current methods of arrangement employed by the HRC.
Before discussing the arrangement we established, it is necessary to note the benefit of arranging digital files is flexibly of those files, or more appropriately access to those files, to move after deposit. Any arrangement established in an electronic institutional repository can be altered for varying purposes of access. In our case, the arrangement we developed to organized ingested files into DSpace could be altered, to some extent, by the end users sorting preferences. We will discuss this later in detail.
We approached the arrangement of the Joyce files in the same manner as we would approach arranging paper versions of the same files. We determined the files would fit neatly into 6 series including: Works, Academic Materials, Correspondence, Storyspace, Third-Party Works, and Personal. The following is the arrangement we developed for the Joyce files.
Figure 1. Arrangement of Joyce’s Files
Series I. Works
(Subseries for each title)
Series II. Academic Career
Subseries A. Scholarly Material
(Conferences, Presentations, Groups, Correspondence about conferences, Bios/CVs, Scholarly works, and Published papers)
Subseries B. Teaching Material
(Reading exercises,Class exercises, Learning objects)
Subseries C. Administrative Material
(Grant proposals, Departmental correspondence, Requests for fellowships)
Series III. Correspondence
(can be arranged by date, subject, or author metadata)
Series IV. Storyspace
Subseries A. Code,
Subseries B. Design
Subseries C.. Riverrun Ltd. (company that created the Storyspace reader)
Series V. Third-Party Works
(subseries for each author/work)
Series VI. Personal
(Address books, Expense reports, Other)
In DSpace terms, our arrangement looks like this:
Figure 2. Arrangement in DSpace Terminology
Community: HRC
Sub-community: Michael Joyce Papers
Sub-sub-community: Series I. Works
Series II. Correspondence
Series III. Academic Career
Series IV. Storyspace
Series V. Works By Others
Series VI. Personal
Collections:
Series I. Subseries A. Afternoon
Subseries B. Twilight
Subseries C. Writing on the Edge
(etc.)
Series II. Subseries A. Scholarly Materials
Subseries B. Teaching Materials
Subseries C. Administrative Materials
Series III. None
Series IV. Subseries A. Code
Subseries B. Design
Subseries C. Riverrun, Ltd.
Series V. Subseries A. Uncle Billy’s Funhouse, Pete Jones
Subseries B. Chaos, Lily Wilson (etc.)
Series VI. None
We attempted to create series that were specific enough to prevent an overlap of possible “homes” for files, but broad enough to encompass a significant portion of the archive. This arrangement is based on how files were created by Michael Joyce. As Joyce creates some files in his role as hypertext author and other files in his role as Vassar professor, we attempted to separate the files in the arrangement. This separation was most difficult when evaluating where written works should be placed. We eventually determined, after looking at Joyce’s own distinctions between fiction and academic works within his 1998 curriculum vita (http://faculty.vassar.edu/mijoyce/MJoyceCV04.htm), that fiction would be arranged in subseries according to title within Series I. Works, and his academic papers would be separated into subseries by cause for creation in Series II. Academic Career. Joyce uses these headings to delineate the types of items he has written: Fiction and Hypermedia; Scholarly Books, published lectures, etc.; and Scholarship. We equated our Series I. Works to his “Fiction and Hypermedia” title. Our Series II. Academic Career is the combination of his “Scholarly Books, published lectures, etc.” and “Scholarship.”
We faced some confusion when trying to sort files. The published titles of some files could not be ascertained from file name, so we had to read through most of the digital files at least once that we were trying to arrange. (As a side note, we often had to read through the files a second or third time when assigning content keywords to the files for ingest.) We also had difficulties separating files into Series I. and Series II. because some academic essays were published individually, then at a later date were published together in Othermindedness. This made it difficult to distinguish under which title we should arrange the files—the essay title or the compilation title Othermindedness. Additionally, some titles were not published at all and therefore not listed on Joyce’s vita. In the instance of unpublished work, we were forced to determine if the file was fictive or academic in nature. The line between narrative work (fiction) and academic material was difficult to distinguish, however, whenever we doubted the arrangement of files, we would turn to the author’s method of distinguishing his work in his 1998 vita.
Despite the size of Joyce’s archive—211 Mb or nearly 4800 files—we were able to arrange all of the files into six series. We found it was exceeding more difficult to arrange digital files in a suitable arrangement, as compared to paper archives, because of the initial disorder of the accessioned files, the amount and initial placement of duplicates and the lack of distinguishing features of files visible to the archivist. Processing digital files required at least three passes through the files to separate them into appropriate series. With each pass, we would break the files down into smaller and smaller groups until all of the files were in appropriate folders corresponding to published titles, groups or other context of creation as listed in figure 1.
Originally the files came into the HRC saved on 370+ floppies. Although we retained the original location, and thus original order, of files by recording disk numbers for each file, we found the original file order to be haphazard and insufficient for research access and file use. We wanted to enhance access and use to the Joyce archive by intellectually organizing the files in a manner that would reflect Joyce’s creation process. The file/disk order in which the files came to the HRC mainly reflected Joyce’s file preservation process. We know that most of the files reflect Joyce’s preservation process because the files on disks were saved as backups to the initial file copy, presumably on Joyce’s hard drive, because most of his disks were labeled “backup” or “b/u.” It is important to note that the files saved on Joyce’s disks reflect his own appraisal. He determined which files should be saved to disk. Since the files on the disks we received were not only created by Joyce and saved to the hard drive, but they were saved again, if not multiple times as backups, by Joyce, we are preserving only those files Joyce intended to preserve. Hopefully, when the HRC receives the files mirrored from Joyce’s hard drives we will find even more files that relate to his process of creation than the initial files we have preserved from his floppy disks. Unfortunately, due to Joyce’s computer upgrades through the years, the files from his early working years, circa 1980s, which were not saved to floppy disk may be lost forever if not migrated to his new hardware.
Differences Between Arranging Paper and Digital Files
Certainly some aspects of digital and paper arrangement are similar. Hierarchical relationships exposed by traditional archival file arrangement into series and subseries can still be utilized in DSpace. Using hierarchical groupings, Archivists may map traditional archival arrangements onto hierarchical groups within DSpace, specifically, onto communities, sub-communities and collections. However, while processing the Joyce files, we discovered a number of differences between arranging paper files and arranging digital files.
Digital arrangement is more flexible than paper arrangement: Flexibility is a key component of DSpace. Items may be ingested into multiple collections by mapping an ingested item from one collection to another. Additionally, since one cause for arranging paper files is to enable easy access, multiple methods of access to files constitute multiple arrangements. One can access an item by searching for subject keywords, performing full-text searches, organizing the display of files within a collection by author, date or title. One of the greatest aspects of digital archives is the flexibility by which files can be arranged. With digital archives, archivists can retain the original order of accessioned files and impose an order that facilitates greater intellectual access.
Digital archives require item level metadata: Item level metadata is required for digital arrangement, whereas with paper files, folder level metadata is the most detailed metadata recorded. Current archival practice dictates arrangement of archival items into related groups. The purpose of group arrangement is to cluster items that were created by a similar function together. Clustered items may provide more contextual clues than individually arranged items, and thus reveal more information to the end user. Only in instances where items are collected individually, due to rarity or famous association, are those items individually arranged. At the HRC, for instance, manuscripts created before 1700 are removed from the group in which they were accessioned, placed into the Pre-1700’s Collection and receive an individual access record. This is mainly to ensure the rare items are well preserved and to facilitate easier access. In DSpace, items are issued individual access records for the same reasons: preservation and access.
Item level metadata for digital files is the most important component of digital preservation. The more we know about a digital file, the more options we have to preserve it. If we know how and when a file was created, we can find the original or emulated software to read it. We can also find a translating program to read the text in its original format and produce another version readable by available software. Additionally, in the future, new technologies might emerge that could require any type of metadata. The more item level metadata we keep right now, the better chance to read the file in the future.
Item level metadata is also important for accessing digital files. Just as it is difficult to appraise files that are intangible, it is difficult to differentiate digital files from one another. If all files were placed in collection level groups, researchers would waste energy and valuable time trying to distinguish desired files from others.
Terminology differs between paper and digital arrangement: The first main difference between paper and digital arrangement is the use of the term “papers.” Within traditional archives, items created by one person over a period of time gathered together are called papers. Records are items created by an organization as evidence of business transactions. A collection is the compilation of multiple items that were created by multiple authors documenting various actions. Within the scope of these definitions, if Michael Joyce’s digital files were actually paper, we would have called his archive “The Michael Joyce Papers.” Can digital files be called “papers”? In the academic realm, when researchers present their findings at conferences their lectures are called “papers” even if the text of their presentation is born-digital. The University of Rochester’s DSpace repository has a collection titled “Warner School Conference Papers” where digital files with texts of conference papers have been ingested. Although our solution to this problem of terms was to substitute other words for “papers,” such as “digital files”, “material”, “files”, “items”, and sometimes “collection,” if the term “papers” carries a meaning that already implies more than tangible documents, it is appropriate to title our compilation “The Michael Joyce Papers.”
The second issue with traditional archival and digital arrangement terms, specifically within DSpace, concerns DSpace’s hierarchy terminology. DSpace documentation differentiates communities and collections. “Each DSpace site is divided into communities; these typically correspond to a laboratory, research center or department. As of DSpace version 1.2, these communities can be organized into an hierarchy. Communities contain collections, which are groupings of related content.” Based on these definitions, communities would correspond to the creator(s) of digital items and collections would correspond to the content of the items. In our arrangement (see Figure 4.) communities and sub-communities refer to differences in creator and content. Preferably, we would have mapped our series as collections on DSpace because our series were established due to content differences. Unfortunately, due to limitations of DSpace 1.2, collections are shallow and may contain items only, not sub-collections. We need deeper levels of description in collections instead of communities.
Suggestions to Facilitate Archival Arrangement
Traditional archival theories can and must be integrated into institutional repositories best practices. Both archivists and DSpace administrators have the same goal in mind: digital file preservation. We have a few suggestions to merge archival methods and digital preservation within DSpace.
First, DSpace hierarchy should be deeper at the collection level and allow for sub-collections to facilitate representative content distinctions between collections and sub-collections. Using sub-communities as content distinctions is not the imply intent within DSpace 1.2 documentation.
Secondly, collection administrators should be given options to alter templates for item ingest and display in the web-based user interface. The main benefit of digital arrangement is the flexibility by which users can arrange items. If, item record lists (found within collections) display only title, author and date issued, users have limited choices for arrangement. Title, description, author, date created, and date issued should be fields listed in item lines when displayed at the collection level. End users will want to sort by those fields.
Third, DSpace and EAD records can work together. EAD files can act as the liaison between traditional finding aids and DSpace. The use of an <extref> tag can link the lowest level of description within an EAD file (essentially at “folder” level) to the corresponding level of description within DSpace (in our case, the collection level.) See Appendix A. for an example. Linking EAD files to DSpace records gives end users more opportunities to access information recorded in DSpace hierarchies. It also provides a smooth access route for users who want item level information but cannot find such detail from traditional archival sources.
Finally, software tools to extract content and creation dates of files would greatly reduce the time spent on arranging digital files. If we had passed our files through a software tool that could have extracted subject keywords from the files, our subject metadata would have better reflected the content of the files. Although automatic keyword extraction is not the ideal way to assign keywords, it would have been better than the method we employed, which was to skim the file and assign keywords that we thought we pertinent. Our system was flawed because none of us assigned similar keywords, our subject evaluation was based on a cursory glace, our keywords were not based on a standard vocabulary, and often we assigned no keywords because we could not access the file at the time of ingest. Additionally, we would have saved time if the creation dates of our Mac files were automatically extracted instead of manually entering the metadata field for creation date and the value for the field after each file had been ingested into DSpace.
The Appraisal Process
In the Archival Terminology of the International Council of Archives (ICA, 1984) appraisal is defined as: "a basic archival function of determining the eventual disposal of records based upon their archival value”. Appraisal is also referred to as evaluation, review, selection or selective retention. If we consider this definition, the appraisal process would not present a difference between paper-based archives and electronic archives. In fact, the decision of the HRC to collect Michael Joyce’s materials was based in their “archival value,” and this value is related to HRC’s collecting policies. Nevertheless, the differences between paper archives and electronic archives appraisal only becomes apparent when the process is undertaken. Differences in following areas are discussed below: author identification, mode of creation, distinguishing files, disposal and rights management.
One of the first issues that we noticed, while working with Joyce’s digital records was the fact that many clues that one uses when working with paper documents are not present in the electronic environment. For example, when the author did not explicitly insert his name in the text and the document was not clearly perceived as being his, we could not count on handwriting analysis, letterhead, type of paper, ink color, ink type, smell, type of copy, and other clues that are generally applied in the paper contexts. We were completely dependent on the language that was used and the content of the file, which sometimes could be quite misleading. In some cases it took two of people working through the documents more than once to try to find more clues to identify not only the author, but also what the file actually was. Despite these disadvantages, there are advantages in terms of identification unique to digital files including: potential date stamps, the type of software used, e-mail headers, MD5 hashes (to differentiate copies), and creator metadata attached to files by newer software. These electronic identifiers may not be failsafe, however, they do provide alternatives to tangible differences between paper files.
The second issue is the mode of creation of digital files and the difference with paper documents. Given the possibility of keeping different versions of a record and also making backup copies on diverse media (hard-drive, floppies, etc.), people tend to have multiple copies of the same file or files differing in only in system metadata rather than content. The ease of copying digital files facilitates the creation of more duplicates than with paper files, and digital duplicates seem more widely disperse that paper duplicates. In paper files, carbon copies are usually found near the original copy. This is not true with digital files. In our project the discs received were usually backups1. Even though the amount of duplicates or near duplicates was not significant, it required work on our part to identify them, to keep all the different versions (even when the changes were minimal) and to “dispose” the exact duplicates. The random assortment of files in the floppies, also lead to difficulties identifying the pertinent “associations” of the files, which made this task very time-consuming. In addition, our team members’ current experience with paper documents made these tasks a challenging learning experience. Finally, an obvious difference is that digital files are “saved” multiple times over the course of creation, which destroys previous versions. In paper archives one might encounter not only several copies of the same document in different locations, but also different versions might be kept, which makes it possible to track changes and compare them with the final document. This process is usually lost with digital records unless all the changes are not saved separately or software versioning features are implemented.
The third issue is that of distinguishing and identifying files which is technologically dependent since a reader is required to access the contents of a digital file. When the files could not be opened because of the lack of the appropriate software, the information could not be accessed, which meant that some records could not be identified. This is something that with paper documents does not occur, since a glance can distinguish at least the type of document. With electronic records we initially relied upon the name of the file to begin our identification process. With older software, however, where filenames were shorter, the filenames frequently were either misleading or just not indicative of any particular content. This forced us to classify some records as “Unidentified.” Interestingly enough, once we had processed many files, we began to recognize Joyce’s file naming patterns2. Finally, the loss of file associations was another recurrent problem. Simply identifying the appropriate application to use for opening a file proved to be difficult in many cases since the workstation did not have the requisite software installed. For example, before we installed Storyspace on our computer, we would se a generic file icon instead of the Storyspace icon.
Disposal is an important archival process related to the life cycle of the records. Disposal is “the action taken with regard to non-current records following their appraisal and the expiration of their retention periods as provided for by legislation, regulation or administrative procedure. Frequently used as synonymous with destruction.” Related to disposal is a practice called weeding that is “the removal of individual documents or files lacking continuing value from a series.” (ICA, 1984). As we stated before when we were dealing with appraisal, the definition of disposal could be theoretically applied to electronic records, but in the practice we noticed there were some differences with a paper-based archive. These will be addressed in relation to disposition and right management issues.
Even though from a traditional archival perspective there are files that during appraisal could be disposed of from Joyce’s fond, the HRC will keep all the “original” materials contained in the floppies, as well as backups of all the materials that were produced while implementing this project. This brings up a different approach that we would have had in a paper-based collection, where if we dispose the materials, they are removed and destroyed. In the case of these electronic records even if we could have taken the same procedure, and delete the disposed records, the HRC will keep the “originals” and the back-ups, the disposal process instead becomes an access restriction for the selected materials. The “disposed” files were not included in appraisal directory and final arrangement, and consequently, not ingested into DSpace. There are three groups of materials that were disposed: software applications files, duplicate files, and files that contained student works. The software applications files were not kept because they were not part of what we considered Joyce’s fonds because he did not create them. The only software that was kept was related to Storyspace because of its uniqueness to this collection, since it is part of the author’s artistic and academic development, and because of Joyce’s involvement with the creation of Storyspace. It is likely that the HRC will acquire some rights to keep Storyspace software, the new version of which will be installed in the reading room computer in order to view Joyce’s hypertext novels.
The second group of disposed materials was composed of duplicates. These files were readily identified by comparing MD5 hashes generated during the creation of the file index. Further, we checked that the dates (creation and modified date), the format and the size of the file were all exactly the same in order to be assured that we were disposing exact copies. There were some cases were one word changed from one file to the other and we kept both versions. For example, the poems “Eislied: a melody in black and white” and “A melody in black and white” are identical poems with one word inserted in the first title. When we disposed the duplicates we kept the one that was first according to our disk folder number. In order to keep his working style for posterity, we considered documenting in the metadata the identification number of the duplicates to make the relation accessible to researchers, and possibly model the relationship in the digital repository.
The third type of materials disposed were third-party works that were not created, all or in part, by Michael Joyce. We disposed of student works because they protected by copyright law and it is HRC policy to remove student works from collections. As for non-student third-party works, we originally intended to remove those as well due to copyright restrictions. However, since third-party works are maintained in paper archives, we were instructed to retain those works as we would if they were paper. We created a separate series, Series V., for third-party works and will make it inaccessible until copyright permissions are gained by the HRC.
Appraisal and disposition practices are related to preservation issues. From a practical point of view, a good appraisal process is the first step in the preservation of documents as it ensures that the documents that are retained are well preserved. It is also important to note that according to the InterPARES Project (2002), the assessments of authenticity as well as the feasibility of preservation are criteria for appraisal decisions. Finally, from a theoretical point of view, the relationship between the appraisal and the preservation of cultural property implies a certain perspective on the ideas of uniqueness and permanence. In this sense, only some records will have an enduring value, and therefore will become archival documents that represent our cultural heritage, as in the case of Michael Joyce’s digital fonds.
Preservation
Paul Conway (quoted in Gilliland-Swetland, 2000) states that: “The digital world transforms traditional preservation concepts from protecting the physical integrity of the object to specifying the creation and maintenance of the object whose intellectual integrity is its primary characteristic.” Even though, we have to agree with Conway in the sense of realizing that the preservation of digital objects poses different issues than the preservation of physical objects, in the digital environment physical objects also have to be preserved.
At the beginning of the project, the HRC’s primarily concern was to retain the information and was not so concerned with retaining the original floppy disks after the materials were copied in a secure environment. From the perspective of the preservation of the bitstreams, it is unclear whether future developments will be better able to make these bitstreams more easily accessible. In that sense, if we keep the original objects we will be able to work on them again if we have access to new technology. We should also consider the importance of the original as a representative of a type of technology as well as an archival object and as a proof of authenticity of the files and documentation of their existence. Therefore, we highly recommend keeping the floppies as evidence of the “originals.” As physical objects they should be housed in archival quality boxes designed for this type of material and in an optimal environment, which will require insignificant expenditures and storage space.
Returning to the concept of future access, we must understand the ideas of William LeFurgy (2002), who is very optimistic regarding the progress of digital preservation, when he proposes a model of levels of service. LeFurgy poses that depending on the type of object that we are faced with and on the state of the art of digital technologies we will be capable of always improving our preservation systems and our levels of services for users.
The levels of service, according to LeFurgy, are related to the degree to which the digital materials can be managed independent of specific technology, in other words, their “persistence.” Persistence is directly linked to the conditions under which the records were created and described. Therefore digital collections can have different levels of persistence: optimal, enhanced and minimal, depending on their persistence characteristics. In a low level of service the formats are not recognized and only the bitstream can be preserved. In a medium level, even though the formats are known, bit preservation can be achieved but full support cannot be guaranteed. In a high level of service, formats are supported and therefore both bit preservation and functional preservation are achieved. Using migration or emulation techniques both types of preservation are possible. MacKenzie Smith (2003) states that bit preservation is achieved when digital files are preserved as they were originally created without any changes. Functional preservation is achieved when the “digital file is kept useable as technology formats, media, and paradigms evolve” and the functionality is maintained.
In the collection’s SIP agreement it is stated that a “medium” level of service will be provided, which entails the following:
Partially persistent materials that enable medium confidence. Preserves the content of the material with degradation of the form allowed. For this level of service, the repository will watch the format in order to try to maintain the data in an accessible format. They will, however, not create their own tools for this conversion unless absolutely necessary. For this level of service, off the shelf conversion tools will be used. Checks will be made to verify that the intellectual content is the same. The original bit stream will be maintained in addition to the converted file. Formats enjoying this level of service include compression schemes and open but proprietary standards.
Initially, the HRC was not very concerned about keeping the look and feel of the original files as the priority was on retaining the information. As the project progressed it was further discussed that, especially in the case of the hypertext novels where the aesthetics plays a major role, the importance of retaining as much as possible of the “look and feel” is of concern. We had access to the new version of Storyspace, so the hypertext novels at the moment are accessed with the limitations of the available version and technology. This leads us again to the issue of the levels of digital preservation, discussed by Smith (2003) because we were able to keep, to a certain point, the two levels of preservation because the new version of Storyspace allows us to retain the functionality of the files even if the “look and feel” is not exactly the same as when they were used originally. Emulation was considered to recover “look and feel,” but disregarded because the files could be accessed with the new version of Storyspace.
Kenneth Thibodeau’s (2002) definition of the digital objects as being physical, logical and conceptual objects is appropriate to summarize some issues related to preservation of digital objects in the long term. For this author: “A physical object is simply an inscription of signs on some physical medium. A logical object is an object that is recognized and processed by software. The conceptual object is the object as it is recognized and understood by a person, or in some cases recognized and processed by a computer application capable of executing business transactions.” He states that in order to preserve the digital object we must identify and retrieve its digital components. In this sense “The process of digital preservation then, is inseparable from accessing the object” and that is why for the author “the black box for digital preservation is not just a storage container: it includes a process for ingesting objects into storage and a process for retrieving them from storage and delivering them to customers. These processes, for digital objects, inevitably involve transformations.” As we have seen, our project has exposed us to compromising the type of transformations that would be acceptable, in order to keep as much as possible the “original” look and feel of Joyce’s materials.
According to the OAIS (2002) there are two types of transformation: reversible and non-reversible. In the preservation field this concept is controversial, because we know that even if we use reversible techniques and materials it is impossible to reverse a conservation treatment without changing the object in a certain way. We would argue that complete reversibility is impossible both with traditional physical objects and in digital objects. Migrating from one version of a format to the next carries some sort of difference between the original bitstream and the new one, therefore it is important not only to note that the change was made, but also to keep the original version.
During the project we considered migration as the preservation strategy that we could use in order to access some of the digital records. We migrated the MacPaint files to Portable Network Graphics (PNG) files using a freeware application that is capable of batch processing. We did not migrate Storyspace, Hypercard, and HTML because these file types are still accessible using current software. Finally, MacWrite files could neither be opened nor migrated because the original software cannot run on the newer Macintosh operating systems and conversion cannot take place using anything other than specific commercial software. Microsoft Word and Excel files comprised the majority of the document types recovered, but conversion one-by-one was deemed to be too labor intensive without the use of commercial software capable of batch conversion. Furthermore, these files are still accessible using the Macintosh version of Microsoft Office.
Collection Implementation & Ingest
Appraisal and the resulting metadata complete the necessary preparations prior to ingest of the documents into the digital repository. DSpace version 1.2 was used to create a digital repository of the Joyce works, starting initially with a small portion of the total documents in order to test and verify procedures to be used for implementation. Two major tasks were accomplished during this test: the development of the repository structure and access rights, and the ingest of documents.
A hierarchy of communities and collections must be created prior to ingesting materials into DSpace. Before these can be created, however, access controls must be designed for defining both access to collections and the submission workflow process. DSpace currently allows two levels of administration: one for collection level administration (Collection Administrator) and another for global administration (Site Administrator). Unfortunately, there is no administrator role for community level administration, so in order to create the communities and sub-communities within DSpace, Site Administrator permissions were granted to one of our group. The collection structure, workflow assignments, and permissions regime had to be established during the short window in which Site Administrator permissions were granted.
The first step in the administration process is to create the community-collection hierarchy. DSpace allows a nested community structure where each community may contain both collections and sub-communities. The nomenclature used by DSpace immediately came into conflict with the nomenclature used in archival practice, where a collection is a hierarchy of series and sub-series. It seemed intuitive at first to create a community to identify the institution holding the collection (HRC), then create a master collection for the Joyce works and subordinate categories for the series that had been defined during appraisal. Unfortunately, DSpace does not support a hierarchy that is analogous to a series, not even nested collections. To remedy this problem, each series was assigned to a sub-community which would then hold collections for each sub-series. If a further level of sub-series were required, another sub-community would be created under the series community. Thus, the nomenclature used in DSpace to model the collection redefined series as communities and inverted the relationship between series/communities and collections. This subtle distinction is likely to create confusion as DSpace is implemented in archival endeavors.
Workflow steps had to be defined concurrently with the collection structure. DSpace has a workflow and permissions structure that allows individual users (E-people) and groups of E-people to be assigned to specific workflow steps. Up to three roles may be assigned, including accept or reject submission, edit metadata, and edit metadata with accept or reject ability. When deciding which workflow configuration to use, two possible alternatives were devised: one assumed that Michael Joyce or a designated representative would be allowed to submit items to the collections, and the other considered that HRC staff would submit all items to the collections (see Figure 3). The former workflow process requires more steps for review of submitted documents and metadata review owing to the notion that the submitter may not completely describe the submitted item. The latter workflow process assumes that a minimum of supervision is required when trained staff is responsible for submitting items to the repository. The latter case was implemented.
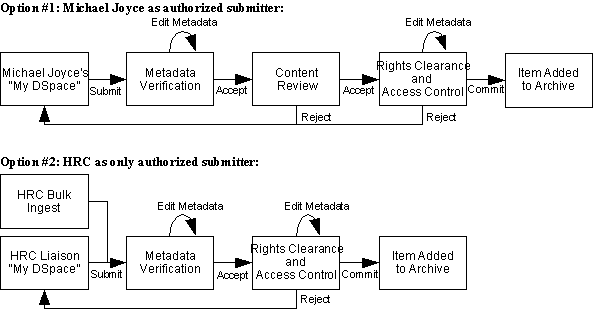
Figure 3: Proposed DSpace workflow.
In addition to workflow establishment, access rights must also be assigned during the establishment of the collection. DSpace allows the assignment of read and/or write permissions on each level from bitstream to collection to community. The SIP agreement and HRC policies dictated that access to the bitstreams in the collections be restricted only to HRC patrons on the HRC premises. Additionally, submission of items to the repository would be restricted to designated HRC staff. For purposes of creation, all bitstreams were restricted to the collection administrators, while the public was allowed to read the listings of collections and items in the repository. Once the collection is completed, a special E-person will be created with certificate access from a designated workstation in the HRC reading room that will be allowed read access to all materials in the Joyce collection.
One series out of the entire collection – Works – was chosen to comprise a pilot ingest to test the assumptions and decisions made up to this point. Upon completing each of the previous steps, a hierarchy with permissions and workflow procedures was in place for each of the works (DSpace collections) within the Works series (DSpace community). A final set of decisions had to be made before ingest about how to handle items within each collection. The number of individual documents within each work varied from one to hundreds, which may be further graded by the different versions and instances. DSpace defines Items as the container for bitstreams within collections, which may contain Bundles of bitstreams or a single bitstream. Metadata is defined at the Item level with limited metadata for each bitstream (e.g.: file identifier, file size or extent, checksum, etc.).
During the digital archeology and appraisal processes, metadata was collected for each bitstream that goes beyond that which DSpace captures (e.g.: creation date, modification date, etc.). This left us with a quandary about how to represent each semantic item within DSpace and still maintain the maximal amount of bitstream-level metadata. One solution to this problem is to create an item for each bitstream that would allow the maximal amount of metadata to be captured for each bitstream. Unfortunately, this approach would require a separate item for each file, which could number into the hundreds for each work, and would not group the bitstreams in the context of other bitstreams that were originally grouped (such as Web pages). Alternatively, an item could bundle all applicable bitstreams, to include migrated or converted versions, within the same DSpace item. Although this approach maintains maximum context, the accuracy of the metadata suffers.
The solution chosen for this implementation was to create a separate DSpace item for each semantic grouping (version, etc.) while keeping converted “use copies” together with the originals to allow users a choice of which version to view. Descriptions can be attached to a bitstream that can differentiate conversions from originals, while using a similar filename. Additionally, the item's provenance description field can be modified to record the applicable migration actions. In this way, the metadata that describes the semantic grouping remains intact while providing new versions for users in an appropriate context. Unfortunately, one problem remains in that each version of a work (DSpace item) within a collection has the same title, and DSpace does not present enough information at the collection level to differentiate between versions. It is poor practice to alter the title metadata to accommodate the differentiation of versions within the DSpace user interface – other metadata fields should be used to convey the distinction.
Observations on Working with DSpace
DSpace has a very thorough and robust data architecture, unfortunately, there are a number of implementation issues that arose during the course of the creation of the pilot collection that should be noted. The vast majority of problems that were encountered can be attributed to the user interface and intervening business logic. This is not a critique in the guise of user interface design, since the appearance and layout (look & fell) of a Web service is ultimately a question of style and organizational requirements. Rather, the problems encountered appear to be the result of incomplete implementation of the data model and inconsistencies in the user interfaces used in administering collections and submitting content.
For example, some of the most inconsistent interfaces were those involved in the management of workflow and permissions. Site Administrators may create groups of E-people to ease administration of permissions and workflow. A group may be assigned which can be changed at will in one place instead of having to change permissions at each access point. This is analogous to time-tested procedures in systems administration. Unfortunately, when creating a new community or collection, one is forced into a Web form for setting permissions that does not allow access to these pre-defined groups. One must set an arbitrary assignment, and then go back to the collection or community edit dialog to invoke a different Web form that will allow the assignment of an existing group. This creates another problem in the form of multiplicitous “default” groups created in the interim that clutter group selection dialogs across all applicable user interfaces. This is a clear example of a logical data design that is not properly implemented in the user interface.
Other critiques of and major problems that were encountered with DSpace are described below.
Macintosh file issues: Most of the discs processed for the Joyce collection were Macintosh formatted. First, DSpace uses MIME type identification based on Windows file extensions. Macintosh files do not use file type extensions in the filename, but use a creator code that is embedded within the file, which prevents DSpace from automatically recognizing the file type. Second, Macintosh files, particularly executable files, have more than one bitstream; they are split into a resource and data fork. When uploading such a file via a Web form, the data fork is the only part that is sent, therefore, when verifying a checksum, the data fork is all that is necessary to pre-compute.
For most files, the only effect this distinction has is to remove filesystem metadata from the bitstream. If a file type is not manually set during ingest, the user may have no idea what to use to open the file since the identifying metadata was stripped in the process. For executables, however, functionality may be lost altogether. Thus, it is best when transferring Macintosh files over non-Macintosh networks to use some sort of file packaging scheme such as MacBinary, HQX, or Tar.
These issues are not so much a problem with DSpace as much as they are a persistent problem encountered as the result of working with Macintosh generated files.
Metadata interaction: Two major issues were observed pertaining to metadata generation and workflow. First, for the majority of the items in our collection, the main author is a constant; therefore, it is preferred to not have to enter the author field for every submission. Unfortunately, the interface did not carry default values set at the collection level into item level metadata.
Second, when establishing workflow steps, we were under the assumption that the metadata editor would be permitted to edit more than the basic metadata presented to the submitter. Unfortunately, the same exact forms were presented to the metadata editor. This amounts to nothing more than a proofreading step and not a comprehensive metadata check as implied in the documentation. Detailed metadata editing can only be performed by collection administrators from the item editor.
Item importer as an automation tool: The item importer or bulk ingest utility was used for a number of items that contained many bitstreams. Any sub-series containing more than 10 bitstreams was selected for bulk ingest. The item importer saves a significant amount of time for ingest, but unfortunately, it can only be invoked on a per-collection basis, once at a time. In other words, if one wishes to import many items into more than one collection, separate commands must be issued for each collection and the file import configurations and metadata must be separated. The item importer would be much better as an automation tool if there were some way to map items to different collections.
Item importer issues: Numerous idiosyncrasies were encountered when invoking the item importer. First, a metadata file, expressed in Dublin Core, is required for each item to be ingested. The system crashed upon execution if any of the elements in the metadata file were empty (i.e.: no text value provided). Since empty elements in XML are completely valid, this sort of behavior should be anticipated by the XML parser to prevent such errors.
Second, the item importer requires a per-item content listing. This feature seems to be something of an evolutionary holdover given that the Java framework could easily recurse the item directory to get a file listing, ignoring the metadata file, rather than relying on accurate generation of a contents listing by the user. Furthermore, if an item should happen to contain a bitstream with the filename “contents” (as occurred once during this project), then a conflict occurs that requires either reversion to manual ingest, or a change to the original file to accommodate the system's architecture.
Finally, the item importer will crash if it encounters a file in the import directory. The system is expecting to recurse a directory and throws an error when the bitstream is encountered. Java should be able to differentiate a file from a directory and ignore it to prevent such errors.
Web page rendering issues: DSpace can render Web sites and pages within the user interface by making a special handling exception for recognized HTML files. The interface also makes exceptions to allow navigation and link embedding within such pages if they are part of the same item. Unfortunately, the bulk ingest process seems to confound this process. Although the items are properly ingested into the same item grouping with the same handle, each bitstream is assigned an index number within the item. Therefore, each bitstream is effectively blocked from seeing the others, thus rendering linking and images non-functional. The effective rendering of archived Web sites remains a major hurdle for DSpace.
Semantic Divergence: Other problems arise because of the semantic divergence between archival practice and the DSpace framework as described earlier. The treatment of licenses in the DSpace system illustrates this problem. When an item is submitted to DSpace, a generic, site-wide license is appended to the item in the form of a text file. This license is identical for all submissions to the system, regardless of the actual terms that may be defined externally to the system by a SIP or other agreement. Additionally, publication date is preferred over such things as date of creation. Such behavior is understandable if one takes the idea of a single organization running DSpace for a single purpose – particularly, that of a publishing-oriented institutional repository. The Joyce files alone have three different rights regimes governing the various series, which renders inappropriate the idea of a single, site-wide license structure. This issue, in addition to the collection implementation challenges addressed earlier, are examples of how the DSpace assumption of “one size fits all” is problematic for translating archival practices into DSpace implementation. The software may be re-programmed to accommodate these issues, but it is unclear how such customization would affect software upgrades and interoperability between DSpace instances, as is required for succession of control between repositories.
In summary, these are all important issues to consider for improving DSpace as an archival platform, but it should be noted that the scope of the project that the DSpace federation has undertaken is massive. The work performed thus far is exemplary and the criticisms put forth here should not be taken as an invalidation of the efforts to date.
Conclusion
As Kenneth Thibodeau (2002) stated “The preservation of digital objects involves a variety of challenges, including policy questions, institutional roles and relationships, legal issues, intellectual property rights and metadata” and during the project we certainly proved that all these issues were involved. Participating in this project we discovered digital preservation is fraught with technical difficulties and unexpected problems. We are fortunate that much of the technology that is currently becoming obsolete is still to a great degree available and that there are people that still have the skills and knowledge to use it. Such luxuries will not persist as hardware and software for legacy systems becomes scarce and the required knowledge fades. As demonstrated, even using emulation or other simulations will not preclude the necessity for adequate tools for digital archeology and appraisal. Archives today are woefully unprepared for the massive change that is about to envelop them as digital preservation needs increase. We hope projects like this will reveal to institutions across campus and across the world the need to take action and preserve our digital heritage now.
Notes
1 It is interesting to highlight that when we began the project, we noticed that many floppy labels said: “b/u”. At first we did not understand what it meant and we even read “blu” because sometimes the handwriting was not clear enough. As the project progressed, we realized that “b/u” and “blu” meant “backup”.
2 It was interesting though, that for example the word “contour” was widely used for different types of files. Contour was part of the name of a published work, but as this was also an important concept, as in “contours of consciousness”, for him. Joyce used “contour” as a title to identify files where he discussed topics related to this concept, but we were unable to distinguish where the file belonged in our arrangement. We finally determined all files relating to contour or contours were relative to our Series II. Subseries A. Scholarly Material, as they were published works from his academic career.
References
Consultative Committee for Space Data Systems (CCSDS, 2002). Reference model for an open archival information system (OAIS). Retrieved from http://www.ccsds.org/documents/650x0b1.pdf .
Gilliland-Swetland A. (2000). Setting the stage. In Introduction to Metadata: Pathways to Digital Information. Retrieved from http://www.getty.edu/gri/standard/intrometadata/2_articles/index.htm
International Council of Archives (1984). Dictionary of archival terminology. New York: ICA.
LeFurgy, W. (2002). Levels of service for digital repositories. D-LIb Magazine (May 2002). Retrieved from http://www.dlib.org/dlib/may02/lefurgy/05lefurgy.html.
MacKenzie S., et al. (2003). DSpace: An open source dynamic digital repository. DLib Magazine(January 2003). Retrieved from http://www.dlib.org/dlib/january03/smith/01smith.html .
Thibodeau, K. (2002). Overview of technological approaches to digital preservation and challenges in the coming years. In The State of Digital Preservation: An International Perspective. Washington, D.C.: CLIR. Retrieved from http://www.clir.org/pubs/reports/pub107/pub107.pdf.
US-InterPARES Project (2002). Findings on the preservation of authentic electronic records. Retrieved from http://www.gseis.ucla.edu/us-interpares/pdf/InterPARES1FinalReport.pdf.
| Attachment | Size |
|---|---|
| joyce_app_a.xml | 18.36 KB |
